Sorting algorithms are everywhere. In filesystems, databases, in the sort methods of the Javascript & Ruby Array class or the Python list type.
There are many algoriths but I believe some of the most known methods of sorting are:
Merge sort divides the list (array) of elements in sub-lists and then merges the sorted sub-lists to finally produce the complete sorted sequence. Wikipedia offers great pseudo-code and I implemented this on my example. It uses recursion for the division in sub-lists and because of the divide-and-conquer logic it can be also parallelized.
Implementation
We start by writing the the main function that divides our list to two sub-lists and then proceeds with sorting each individual sub-list:
def merge_sort(a_list):
length = len(a_list)
if length <= 1:
return a_list
middle_index = length / 2
left = a_list[0:middle_index]
right = a_list[middle_index:]
left = merge_sort(left)
right = merge_sort(right)
return merge(left, right)
Let us take it step-by-step:
if length <= 1:
return a_list
Return immediately if the list has only one element, which is a trivial case for sorting. Note that this is also the termination condition for the recursion!
middle_index = length / 2
left = a_list[0:middle_index]
right = a_list[middle_index:]
Find the middle of the list (middle_index) and divide the input list into two distinct sub-lists, left& right.
left = merge_sort(left) right = merge_sort(right)
The recursive part: call merge_sort for each of the new sub-lists, left & right. Let’s say that we have an initial list of 10 elements that needs to be sorted; in the first call of merge_sort the list will be divided into 2 sub-lists of 5 elements. merge_sort will then be called for each of left & right sub-lists. To be exact, the left sub-list must be completely sorted before proceeding to the right. Clearly these two sorting operations are independent and thus are good candidates for parallelisation.
Based on this simple logical deduction, we will later see how Python multiprocessing can be utilized to take advantage of this algorithmic property.As a final step in our algorithm, the two sub-lists must be merged to a single list, where all elements are now in sorting order.
Merging the distinct sub-lists
And the merge function which will merge 2 sorted subists:
def merge(left, right):
sorted_list = []
# We create shallow copies so that we do not mutate
# the original objects.
left = left[:]
right = right[:]
# We do not have to actually inspect the length,
# as empty lists truth value evaluates to False.
# This is for algorithm demonstration purposes.
while len(left) > 0 or len(right) > 0:
if len(left) > 0 and len(right) > 0:
if left[0] 0:
sorted_list.append(left.pop(0))
elif len(right) > 0:
sorted_list.append(right.pop(0))
return sorted_list
Taking it a bit step-by-step again:
while len(left) > 0 or len(right) > 0:
We need to exhaust both lists. Remember that the element count may be different by one element if the total length of the initial list is odd.
if len(left) > 0 and len(right) > 0:
If both lists are not exhausted, then:
if left[0] 0:
sorted_list.append(left.pop(0))
elif len(right) > 0:
sorted_list.append(right.pop(0))
If either one of the two lists is exhausted then continue extracting elements from the non-empty list.
In second thought, this could probably be done in a single step, which will save some computational time:
elif len(left) > 0:
sorted_list.extend(left)
break
elif len(right) > 0:
sorted_list.extend(right)
break
Finally, the function returns the merged list which now contains all initial elements in ascending order.
Observations
For small lists this procedure is rather trivial for the core of a modern CPU. But what happens when a list has a significant size? We talked about parallelization. Without having to modify the code of the functions described previously, we could just divide our list in a number of sub-lists equal to the number of cores at our disposal and assign each to a different process.
Caveat: the final merging will be accomplished by a single core, which is the largest fraction of the algorithm’s time. Nevertheless, the process speeds up significantly for large lists. An additional note, the process of spawning new processes (fork system calls) will notably delay the overall procedure for small lists. Apparently, the amount of time required for creating the objects and handling the multiple processes (let’s call this MP) becomes a less significant factor for large lists, as the percentage of MP over the total sorting time (let’s call this S), diminishes with the increase in the denominator.
Putting it all together
I have written an annotated version of the parallel MergeSort version using Python multiprocessing:
| from __future__ import print_function | |
| import random | |
| import sys | |
| import time | |
| from contextlib import contextmanager | |
| from multiprocessing import Manager, Pool | |
| class Timer(object): | |
| """ | |
| Record timing information. | |
| """ | |
| def __init__(self, *steps): | |
| self._time_per_step = dict.fromkeys(steps) | |
| def __getitem__(self, item): | |
| return self.time_per_step[item] | |
| @property | |
| def time_per_step(self): | |
| return { | |
| step: elapsed_time | |
| for step, elapsed_time in self._time_per_step.items() | |
| if elapsed_time is not None and elapsed_time > 0 | |
| } | |
| def start_for(self, step): | |
| self._time_per_step[step] = -time.time() | |
| def stop_for(self, step): | |
| self._time_per_step[step] += time.time() | |
| def merge_sort_multiple(results, array): | |
| results.append(merge_sort(array)) | |
| def merge_multiple(results, array_part_left, array_part_right): | |
| results.append(merge(array_part_left, array_part_right)) | |
| def merge_sort(array): | |
| array_length = len(array) | |
| if array_length <= 1: | |
| return array | |
| middle_index = int(array_length / 2) | |
| left = array[0:middle_index] | |
| right = array[middle_index:] | |
| left = merge_sort(left) | |
| right = merge_sort(right) | |
| return merge(left, right) | |
| def merge(left, right): | |
| sorted_list = [] | |
| # We create shallow copies so that we do not mutate | |
| # the original objects. | |
| left = left[:] | |
| right = right[:] | |
| # We do not have to actually inspect the length, | |
| # as empty lists truth value evaluates to False. | |
| # This is for algorithm demonstration purposes. | |
| while len(left) > 0 or len(right) > 0: | |
| if len(left) > 0 and len(right) > 0: | |
| if left[0] <= right[0]: | |
| sorted_list.append(left.pop(0)) | |
| else: | |
| sorted_list.append(right.pop(0)) | |
| elif len(left) > 0: | |
| sorted_list.append(left.pop(0)) | |
| elif len(right) > 0: | |
| sorted_list.append(right.pop(0)) | |
| return sorted_list | |
| @contextmanager | |
| def process_pool(size): | |
| """Create a process pool and block until | |
| all processes have completed. | |
| Note: see also concurrent.futures.ProcessPoolExecutor""" | |
| pool = Pool(size) | |
| yield pool | |
| pool.close() | |
| pool.join() | |
| def parallel_merge_sort(array, process_count): | |
| timer = Timer('sort', 'merge', 'total') | |
| timer.start_for('total') | |
| timer.start_for('sort') | |
| # Divide the list in chunks | |
| step = int(length / process_count) | |
| # Instantiate a multiprocessing.Manager object to | |
| # store the output of each process. | |
| # See example here | |
| # http://docs.python.org/library/multiprocessing.html#sharing-state-between-processes | |
| manager = Manager() | |
| results = manager.list() | |
| with process_pool(size=process_count) as pool: | |
| for n in range(process_count): | |
| # We create a new Process object and assign the | |
| # merge_sort_multiple function to it, | |
| # using as input a sublist | |
| if n < process_count - 1: | |
| chunk = array[n * step:(n + 1) * step] | |
| else: | |
| # Get the remaining elements in the list | |
| chunk = array[n * step:] | |
| pool.apply_async(merge_sort_multiple, (results, chunk)) | |
| timer.stop_for('sort') | |
| print('Performing final merge.') | |
| timer.start_for('merge') | |
| # For a core count greater than 2, we can use multiprocessing | |
| # again to merge sub-lists in parallel. | |
| while len(results) > 1: | |
| with process_pool(size=process_count) as pool: | |
| pool.apply_async( | |
| merge_multiple, | |
| (results, results.pop(0), results.pop(0)) | |
| ) | |
| timer.stop_for('merge') | |
| timer.stop_for('total') | |
| final_sorted_list = results[0] | |
| return timer, final_sorted_list | |
| def get_command_line_parameters(): | |
| # Note: see argparse for better argument handling and interface. | |
| if len(sys.argv) > 1: | |
| # Check if the desired number of concurrent processes | |
| # has been given as a command-line parameter. | |
| total_processes = int(sys.argv[1]) | |
| if total_processes > 1: | |
| # Restrict process count to even numbers | |
| if total_processes % 2 != 0: | |
| print('Process count should be an even number.') | |
| sys.exit(1) | |
| print('Using {} cores'.format(total_processes)) | |
| else: | |
| total_processes = 1 | |
| return {'process_count': total_processes} | |
| if __name__ == '__main__': | |
| parameters = get_command_line_parameters() | |
| process_count = parameters['process_count'] | |
| main_timer = Timer('single_core', 'list_generation') | |
| main_timer.start_for('list_generation') | |
| # Randomize the length of our list | |
| length = random.randint(3 * 10**4, 3 * 10**5) | |
| # Create an unsorted list with random numbers | |
| randomized_array = [random.randint(0, n * 100) for n in range(length)] | |
| main_timer.stop_for('list_generation') | |
| print('List length: {}'.format(length)) | |
| print('Random list generated in %4.6f' % | |
| main_timer['list_generation']) | |
| # Start timing the single-core procedure | |
| main_timer.start_for('single_core') | |
| single = merge_sort(randomized_array) | |
| main_timer.stop_for('single_core') | |
| # Create a copy first due to mutation | |
| randomized_array_sorted = randomized_array[:] | |
| randomized_array_sorted.sort() | |
| # Comparison with Python list sort method | |
| # serves also as validation of our implementation. | |
| print('Verification of sorting algorithm:', | |
| randomized_array_sorted == single) | |
| print('Single Core elapsed time: %4.6f sec' % | |
| main_timer['single_core']) | |
| print('Starting parallel sort.') | |
| parallel_timer, parallel_sorted_list = \ | |
| parallel_merge_sort(randomized_array, process_count) | |
| print('Final merge duration: %4.6f sec' % parallel_timer['merge']) | |
| print('Sorted arrays equal:', | |
| parallel_sorted_list == randomized_array_sorted) | |
| print( | |
| '%d-Core elapsed time: %4.6f sec' % ( | |
| process_count, | |
| parallel_timer['total'] | |
| ) | |
| ) | |
| # We collect the list element count and the time taken | |
| # for each of the procedures in a file | |
| filename = 'mergesort-{}.txt'.format(process_count) | |
| with open(filename, 'a') as result_log: | |
| benchmark_data = ( | |
| length, | |
| main_timer['single_core'], | |
| parallel_timer['total'], | |
| parallel_timer['total'] / main_timer['single_core'], | |
| parallel_timer['merge'] | |
| ) | |
| result_log.write("%d %4.3f %4.3f %4.2f %4.3f\n" % benchmark_data) |
Benchmarks
I have executed some test runs on a VPS, which uses a 4-core CPU, Intel Xeon L5520 @ 2.27GHz. However, available CPU time fluctuates due to other VMs consuming resources from time to time. All time measurements are in seconds. The two charts display the change in processing time (y-axis) as a function of the number of list elements (x-axis).
Abbreviations:
- SP
- Single Process Time
- MP
- Multiple Process Time
- MPMT
- Multi-process Final Merge Time
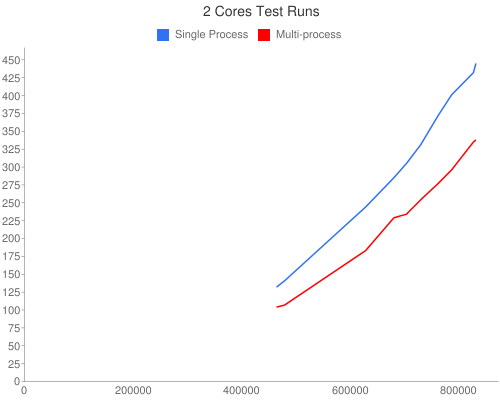
Using 2 cores
| Elements | SP | MP | MP/SP (%) | MPMT | MPMT/MP (%) |
|---|---|---|---|---|---|
| 464,365 | 132.278 | 104.410 | 78.93 | 66.288 | 63.49 |
| 479,585 | 141.993 | 107.780 | 75.91 | 64.916 | 60.23 |
| 628,561 | 244.518 | 183.056 | 74.86 | 114.838 | 62.73 |
| 680,722 | 285.694 | 229.938 | 80.48 | 142.639 | 62.03 |
| 703,865 | 305.931 | 234.565 | 76.67 | 148.318 | 63.23 |
| 729,973 | 330.974 | 254.887 | 77.01 | 162.184 | 63.63 |
| 762,260 | 372.593 | 277.687 | 74.53 | 173.243 | 62.39 |
| 787,132 | 401.388 | 296.826 | 73.95 | 189.222 | 63.75 |
| 827,259 | 432.098 | 335.185 | 77.57 | 212.990 | 63.54 |
| 831,855 | 445.834 | 338.542 | 75.93 | 217.752 | 64.32 |
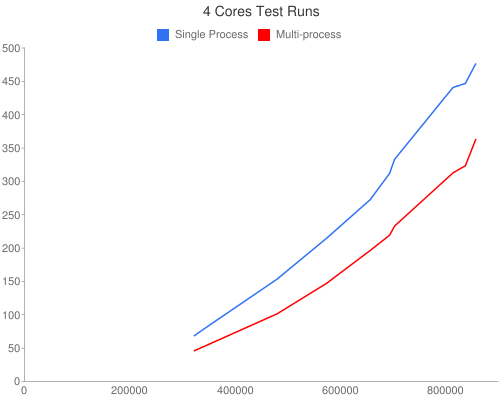
Using 4 cores
| Elements | SP | MP | MP/SP (%) | MPMT | MPMT/MP (%) |
|---|---|---|---|---|---|
| 321,897 | 68.038 | 45.711 | 67.18 | 38.777 | 84.83 |
| 347,426 | 82.131 | 54.614 | 66.50 | 46.272 | 84.73 |
| 479,979 | 153.305 | 101.320 | 66.09 | 87.410 | 86.27 |
| 574,747 | 215.026 | 147.384 | 68.54 | 127.574 | 86.56 |
| 657,324 | 272.733 | 196.504 | 72.05 | 173.142 | 88.11 |
| 693,975 | 311.907 | 219.233 | 70.29 | 191.414 | 87.31 |
| 703,379 | 332.943 | 232.885 | 69.95 | 196.705 | 84.46 |
| 814,617 | 440.827 | 312.758 | 70.95 | 273.334 | 87.39 |
| 837,964 | 446.744 | 323.348 | 72.38 | 283.348 | 87.63 |
| 858,084 | 476.886 | 363.580 | 76.24 | 320.736 | 88.22 |
I would be more than happy to read any comments or answer any questions!

How’s is this supposed to work? you don’t even call a_list from inside parallel_merge_sort?
Hello David! Good observation, this was in fact a rendering issue. I have now added the code as a Gist, so you should be able to view the complete solution.
Hi, the test code runs nicely on my lab’s Intel(R) Xeon(R) CPU E5-2643 0 @ 3.30GHz (4 physical cores, 4 virtual), CentOS
machine. However I run into trouble when asking the code to run with more than 4 cores.
Is this because the script is already assuming that I am specifying the number of physical cores (not the total number of available cores)?
cheers,
aaron
Result with 4 cores:
(Validation passes.)
$ python merge_sort.py 4
Using 4 cores
List length : 238553
Random list generated in 0.327092885971
Verification of sorting algorithm True
Single Core: 15.029496 sec
Starting 4-core process
Performing final merge…
Final merge duration : 9.20412397385
Sorted arrays equal : True
Result with 8 cores:
(Validation fails.)
$ python merge_sort.py 8
Using 8 cores
List length : 108100
Random list generated in 0.164412975311
Verification of sorting algorithm True
Single Core: 3.292262 sec
Starting 8-core process
Performing final merge…
Final merge duration : 0.463366031647
Sorted arrays equal : False
8-Core ended: 0.688715 sec
Hello Aaron,
sorry for the late reply. Just to let you know, I have done several updates in the source code.
Let me know what the results are if you give this another try, thanks!
Hello,
I’m running this program using Python3.4 on a Windows 8.1 machine. All works fine until this line: a = merge(responses[0], responses[1]) #which merges the two sub lists.
I get the following error message:
IndexError: list index out of range
Not sure why this is happening? Any suggestions?
Can you examine the contents of the responses list prior to this line?
is it not at your line 74 your a is already sorted and hence use of merge sort reduces time…I treid usiing b = list(a) and used merge_sort first but nw parallel is showing more time than the serial one
Thanks for commenting but I didn’t quite understand your comment … could you point me to the part of code and the problem you are facing??
Good stuff 🙂
but instead of :
for proc in p:
proc.start()
proc.join()
you should do:
for proc in p:
proc.start()
for proc in p:
proc.join()
actually without this, only one core would run, because proc.join() blocks until the process is done.
Are you sure? I use the top utility to check how many cores are running and also the calculations seem to verify my hypothesis.
You are right there, I have corrected this in the posted code.